Leerdoel: Je gaat zelf een spraakherkenningsmodel trainen om te ontdekken wat daarbij komt kijken
Opdracht
Het Archief Van De Toekomst kan teksten in videofragmenten herkennen. Dus als jij een zoekterm gebruikt, zoals ‘LowLands’, dan zal het archief je alle fragmenten laten zien waarin het festival genoemd wordt.
Om dat mogelijk te maken, is spraakherkenning nodig. Het systeem moet tenslotte gesproken teksten in videofragmenten herkennen om het te kunnen verbinden aan jouw ingetypte zoekterm.
In deze opdracht ga je zelf een eenvoudig spraakherkenningssysteem trainen. Zo krijg je een idee hoe dit in zijn werk gaat.
1. Maak tweetallen en ga naar https://machinelearningforkids.co.uk/ in een webbrowser.
2. Klik op “Aan de slag” of “Get started”.
3. Klik op “Inloggen” en voer je gebruikersnaam en wachtwoord in. Deze krijg je van de docent. (Zie het antwoordmodel voor de docent voor meer uitleg over het aanmaken van een account).
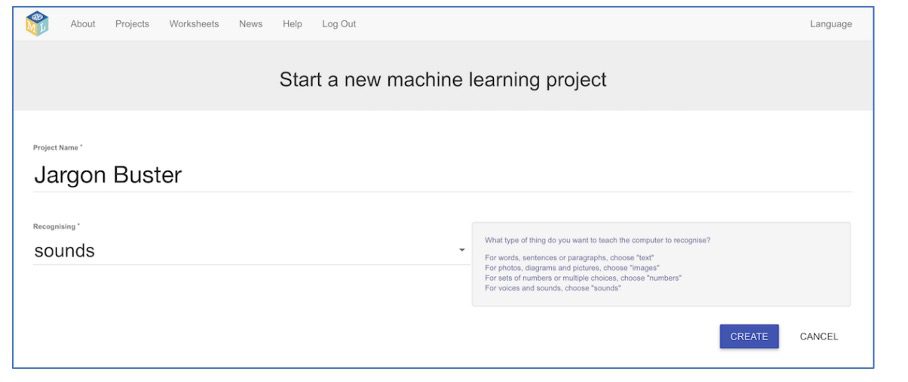
4. Klik als je ingelogd bent op “Projects”, en dan op “Add a new project”. Noem het project “Spraakherkenning”. Vink aan dat het geluiden moet herkennen (“Recognising text”).
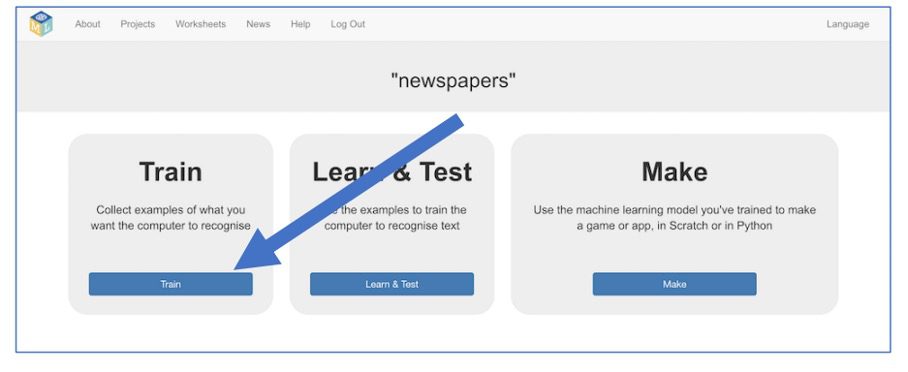
5. “Spraakherkenning” staat nu tussen je projecten. Klik erop. Klik vervolgens op de knop “Train”.
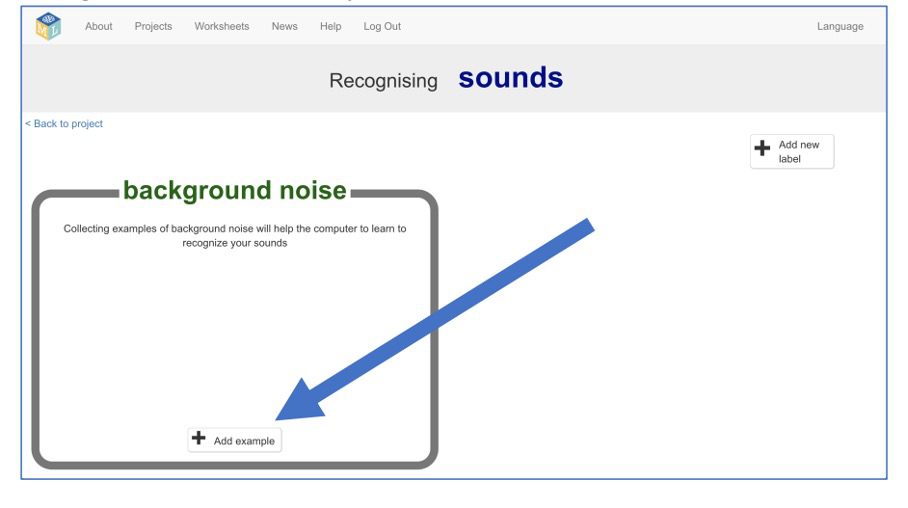
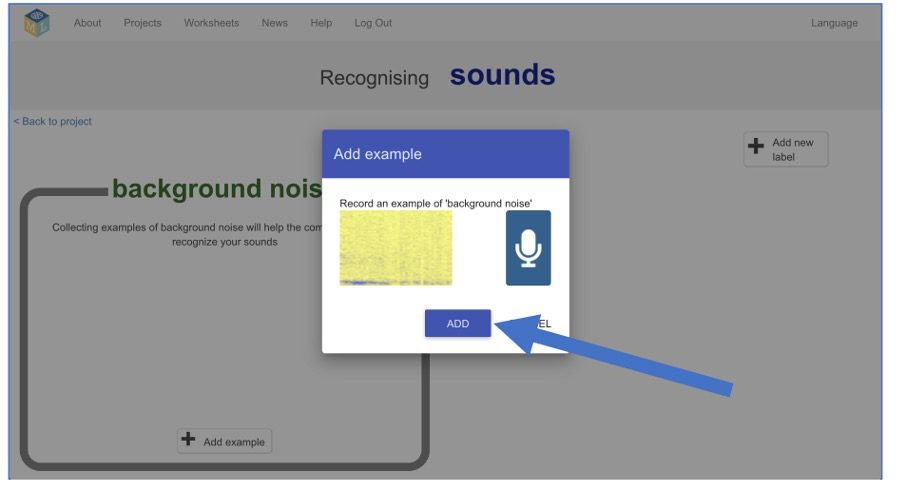
6. Klik op de knop “voorbeeld toevoegen” in het vak met achtergrondruis (“background noise”). Het Machine Learning model leert op die manier het verschil tussen geluiden die ertoe doen en achtergrondgeluiden die het mag negeren.
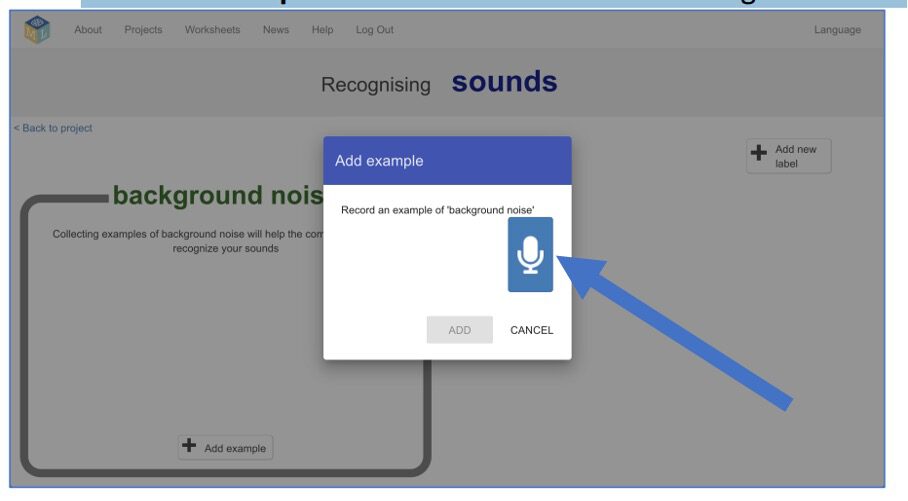
7. Klik op de microfoon om 2 seconden achtergrondgeluid op te nemen. Je hoeft dus niks te zeggen, maar legt de geluiden van de ruimte waar je bent vast.
8. Klik op “Toevoegen” om je geluid op te slaan. Herhaal dit tot je minimaal acht fragmentjes hebt met achtergrondgeluiden.
9. Bedenk nu vier journalistieke begrippen die je je spraakherkenningsmodel wil leren. Maak voor elk van deze termen een vak aan door te klikken op “Voeg nieuw label toe”.
10. Gebruik de knop “Voorbeeld toevoegen” om aan ieder vak minimaal acht voorbeelden toe te voegen. Voor ieder van die voorbeelden spreek je de journalistieke term die je gekozen hebt op een andere manier uit. Met hoge stem, lage stem, met geïmproviseerde accenten. Leef je uit!
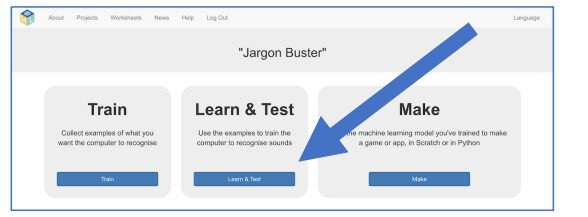
11. Klik op “Go back to project”, linksboven, en dan op “Learn & Test”.
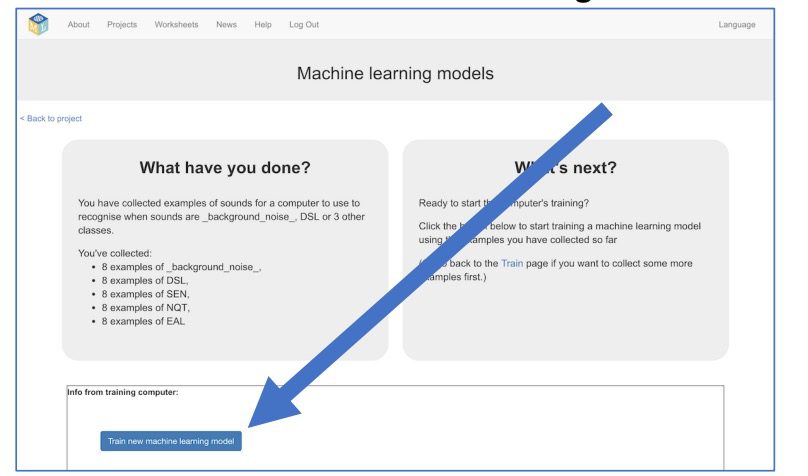
12. Klik vervolgens op “Train new Machine Learning model”.
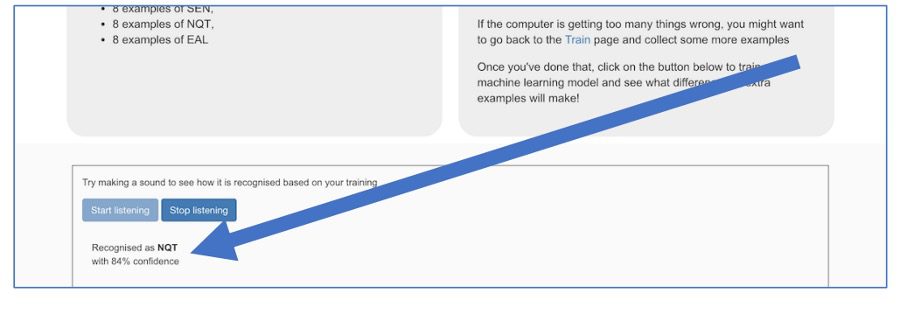
13. Vervolgens klik je op “Start Listening” om je model te testen. Als het model aan het luisteren is, kun je er tegen praten om het te testen. Praat in volzinnen. Het maakt niet uit wat je zegt, maar gebruik zo af en toe één van de woorden die je het model geleerd hebt. Als het model de woorden herkent, zal hij dat laten zien.
Bespreking
Bespreek klassikaal:
Hoe goed werkt je model?
Wat is ervoor nodig om het (nog) beter te laten werken?
Kun je bedenken op welke manier de journalistiek iets kan hebben aan spraakherkenning, naast het Archief Van De Toekomst?
Wat begrijp je van de manier waarop het Machine Learning model met de voorbeelden aan de slag is gegaan? Wat vind je daarvan?
Materiaal
Een laptop voor iedere student (of minimaal één laptop per twee studenten)
De docent moet van tevoren aan account aanmaken bij www.machinelearningforkids.co.uk (voor praktische uitleg, zie antwoordmodel voor de docent).
Tijdsindicatie
20 minuten, waarvan:
5 minuten om het verhaal over Het Archief Van De Toekomst te lezen.
Disclaimer. De onderzoekers hebben geprobeerd alle informatie te verifiëren bij de betrokken media. Waar dit niet is gelukt, is ervoor gekozen om op basis van de beschikbare informatie een zo volledig mogelijk beeld te schetsen van de software die (zeer waarschijnlijk) gebruikt is. De onderzoekers zijn daarbij bijgestaan door AI-experts. Omdat de experts de genoemde AI-toepassingen in meer algemene termen duiden, bestaat de kans op onjuiste details of onvolledigheden. Mocht u deze aantreffen, neem dan gerust contact op.