Opdracht
Smartocto voorspelt onder andere welke kop het beste werkt.
Koppen analyseren kan op veel manieren – van heel simpel tot behoorlijk ingewikkeld. In deze opdracht gaan we een model trainen om een eenvoudige tekstanalyse te doen. Je gaat het leren om in te schatten welke kop bij welk medium hoort.
Daarvoor moet je het model eerst voeden met zoveel mogelijk koppen van De Telegraaf, de Volkskrant, NU.nl en de Correspondent. Bij iedere kop vermeld je van welk medium hij afkomstig is. Dat zijn je gelabelde data.
Met die informatie zet je het Machine Learning model aan het werk. Het gaat proberen om patronen te ontdekken, bijvoorbeeld door te kijken naar woordgebruik of -volgorde, lengte of het gebruik van interpunctie.
1. Maak tweetallen en ga naar https://machinelearningforkids.co.uk/ in een webbrowser.
2. Klik op “Aan de slag” of “Get started”
3. Klik op “Inloggen” en voer je gebruikersnaam en wachtwoord in. Deze krijg je van de docent. (Zie het antwoordmodel voor de docent voor meer uitleg over het aanmaken van een account).
4. Klik als je ingelogd bent op “Projects”, en dan op “Add a new project”. Noem het project “Krantenkoppen”. Vink aan dat het tekst moet herkennen (“Recognising text”).
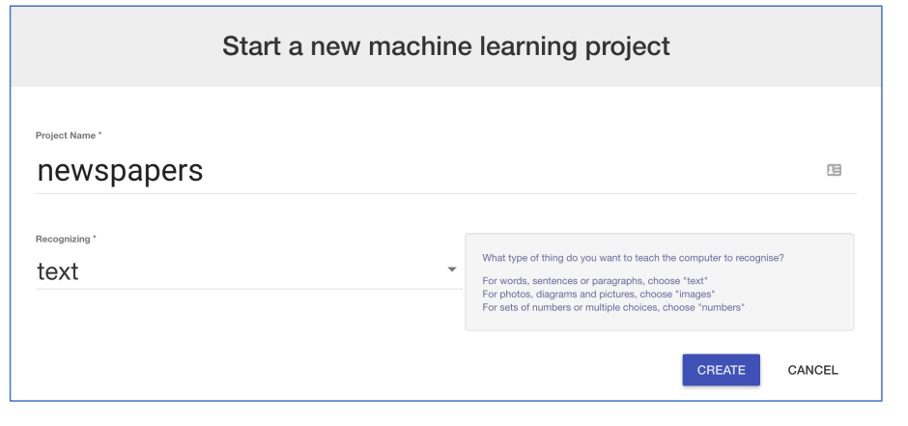
5. “Krantenkoppen” staat nu tussen je projecten. Klik erop.
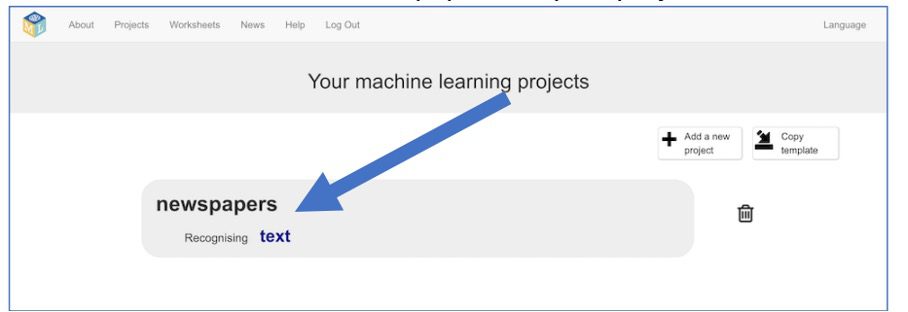
6. Klik vervolgens op “Train”.
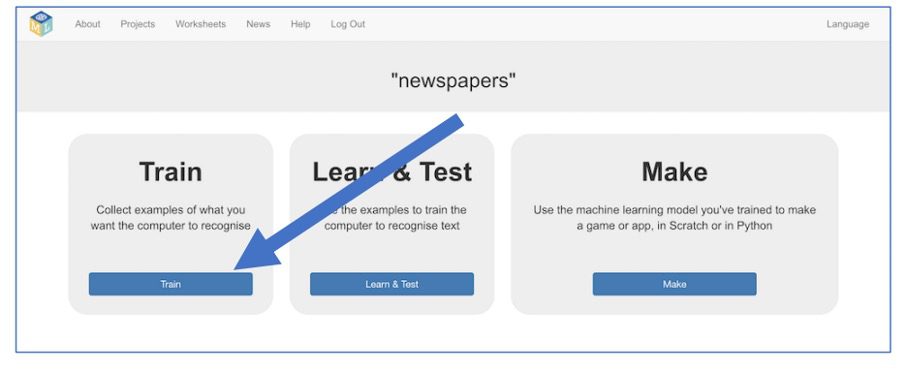
7. Maak eerst een ruimte om koppen van de Telegraaf op te slaan. Klik daarvoor op “+ Nieuw label toevoegen”.
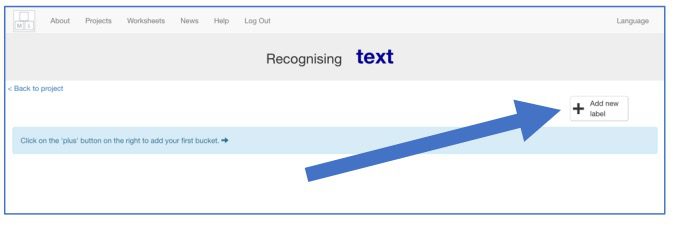
8. Noem deze bucket “Telegraaf” en klik op “Toevoegen”.
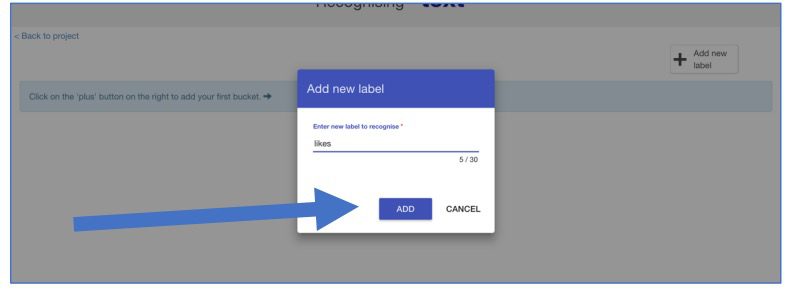
9. Klik nogmaals op de knop “+ Een nieuw label toevoegen” en maak op dezelfde manier een label aan voor de Volkskrant, NU.nl en De Correspondent.
10. Ga naar de websites van deze vier kranten en verzamel zoveel mogelijk koppen.
11. Voeg de verzamelde koppen als voorbeelden toe aan het juiste vak in de projectpagina. Klik op “Add new example”, plak de kop in het tekstvak en klik tot slot op “Add”.
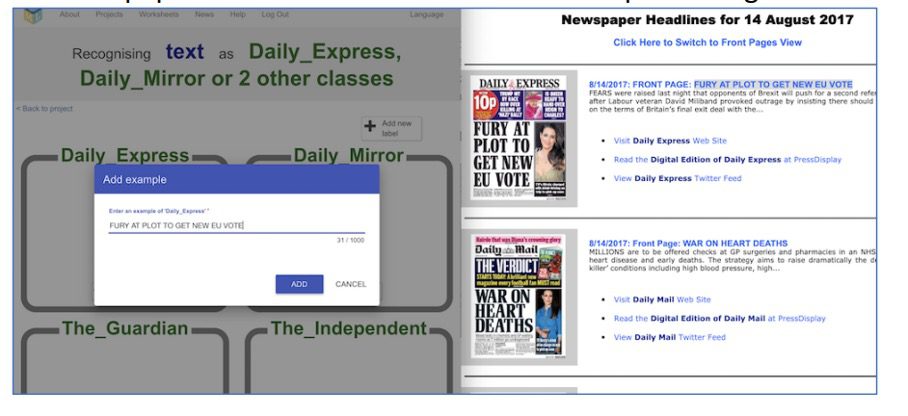
12. Nu is het tijd om het model te trainen op basis van de data (de koppen) en labels (Telegraaf, Volkskrant, NU.nl en Correspondent) die jullie hebben ingevoerd. Klop op “< Terug naar project”, en dan “Leren en testen”.
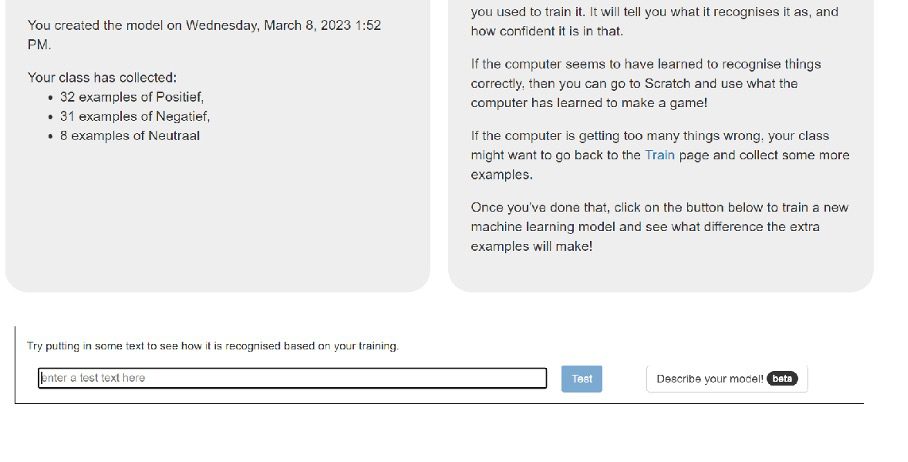
13. Klik vervolgens op “Nieuw Machine Learning-model trainen”. Het duurt een minuut of twee om het model te trainen.
14. Als het model daarmee klaar is, kun je het testen. Voer in het lege vak een kop in van de Telegraaf, de Volkskrant, NU.nl of de Telegraaf. Kies er een die je niet hebt gebruikt als voorbeeld om het model mee te trainen (bijvoorbeeld een kop van wat langer geleden). Klik vervolgens op test. Herhaal dit met verschillende koppen.
Bespreking
Bespreek klassikaal:
- Hoe goed werkt het model?
- Waar komt dat door?
- Hoe kun je het verbeteren?
- Wat begrijp je van de manier waarop het Machine Learning model met de voorbeelden aan de slag is gegaan? Wat vind je daarvan?
- Kun je bedenken hoe dit type model, dat tekst kan leren herkennen, een journalistieke redactie zou kunnen helpen? Tip: Kijk eens rond op deze website. Bij welke andere voorbeelden wordt AI gebruikt om tekst te herkennen of analyseren?
Vervolg opdracht
Klik nu in je projectpagina op “Learn & Test”, en vervolgens op “Describe Your Model”. Daar kun je (kort) lezen hoe het model krantenkoppen omzet in numerieke waarden en ze op basis daarvan analyseert.
Je hoeft de wiskundige uitleg niet te begrijpen. Wat je zal zien, is dat de manier waarop een AI-model naar koppen kijkt, anders is dan hoe mensen ze bekijken. Zelf denk je bij een Telegraafkop misschien aan chocoladeletters of sensationele bewoording, terwijl een AI-model bijvoorbeeld telt hoe vaak bepaalde woorden gebruikt zijn of analyseert wat de woordvolgorde is.
Het model dat je hier getraind hebt, is van tevoren geprogrammeerd. Het is daardoor niet geheel transparant over de manier waarop het werkt. Je voert weliswaar zelf de data en labels aan (de koppen en mediatitels), maar hebt geen zicht op de manier waarop het model daaruit vervolgens conclusies trekt. Wat vind je daarvan?
- Heb je ideeën om de werkwijze transparanter te maken als je dat nodig vindt?
Materiaal
- Een laptop voor iedere student (of minimaal één laptop per twee studenten)
- Een groot scherm waarop de docent zijn of haar laptopscherm kan delen
- Een gratis account bij AIforkids.co.uk (uitgelegd in het antwoordmodel voor de docent)
Tijdsindicatie
35 minuten, waarvan:
- 5 minuten voor het lezen van het verhaal
- 5 minuten voor het trainen van het model
- 10 minuten voor het testen
- 5 minuten voor de bespreking van de test
- 5 minuten voor het lezen van de werking van het model
- 5 minuten voor het bespreken van de transparantie