
Opdracht
De Groene Amsterdammer analyseerde haatdragende tweets gericht op vrouwelijke politici.
Voor deze opdracht ga je zelf een machine learning model trainen om te analyseren wat mensen vinden van Arjen Lubach. Je gaat voorbeelden zoeken van negatieve, positieve en neutrale tweets over hem en zijn programma De Avondshow.
(NB. In overleg met de docent, kun je ook een ander onderwerp kiezen. Let er dan wel op dat je een onderwerp kiest waarover tweets bestaan die in verschillende categorieën passen. Bijvoorbeeld: positief & negatief, haatdragend & niet-haatdragend, etc.).
1. Maak tweetallen en ga naar https://machinelearningforkids.co.uk/ in een webbrowser.
2. Klik op “Get started”.
3. Klik op “Inloggen” en voer uw gebruikersnaam en wachtwoord in. Deze krijg je van de docent.
(Zie het antwoordmodel voor de docent voor meer uitleg over het aanmaken van een account).
4. Klik op “Projecten” in de bovenste menubalk, en kies het project “What Twitter Thinks”. De docent maakt dit project van tevoren aan. (Ook hierover is meer uitleg te vinden in het antwoordmodel voor de docent).
5. Je gaat nu beginnen met het trainen van het model, zodat het leert om positieve en negatieve tweets over Arjen Lubach te herkennen. Klik op “Trainen”.
6. Open een nieuw webbrowservenster en ga naar http://search.twitter.com. Zoek naar tweets over Arjen Lubach.
7. Bespreek in tweetallen welk label iedere tweet moet krijgen: positief, negatief of neutraal.
8. Negatieve tweets over Arjen Lubach voeg je toe aan de bucket “Negatief”. Klik op de knop “+ Voorbeeld toevoegen” in de bucket “niet leuk”.
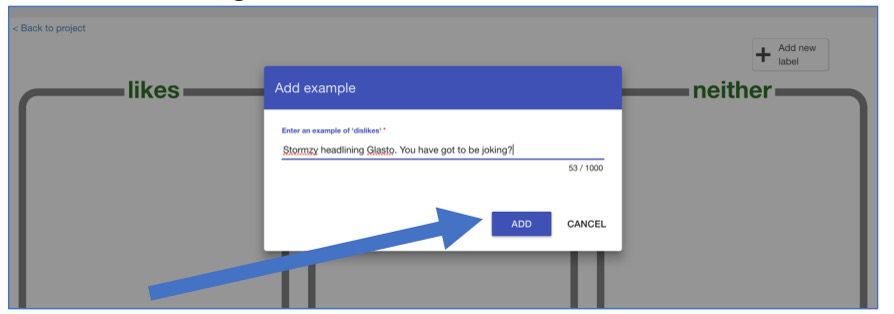
Let op: je kopieert en plakt de teksten uit de tweets en dus niet de URL van de tweets die je in wil voegen.
Plak de tweet in het vak en klik op “Toevoegen”.
Neutrale tweets over Arjen Lubach voeg je op dezelfde manier toe in de bucket “Neutraal”.
Positieve tweets over je onderwerp voeg je toe aan de bucket “Positief”.
Ga net zo lang door tot je in alle drie de velden ongeveer evenveel voorbeelden hebt. Hoe meer voorbeelden, hoe beter het model zijn taak zal uitvoeren.
Bespreking
Als jullie zo’n tien minuten bezig zijn geweest, is het tijd om de labels met elkaar te bespreken.
- Wat is jullie opgevallen bij het bepalen van de labels?
- Over welke tweets waren jullie het oneens? Kun je een twijfelgeval noemen?
- Hoe kwamen jullie tot overeenstemming?
- Wat betekent dit voor hoe goed het model straks werkt?
Vervolg opdracht
9. Nu is het tijd om het model te trainen op basis van de voorbeelden en labels die jullie hebben ingevoerd. De docent deelt zijn of haar laptopscherm op groot scherm, en klikt “< Terug naar project”, en dan “Leren en testen”.
10. De docent klinkt vervolgens op de knop “Nieuw machinelearningmodel trainen”. Het duurt een minuut of twee om het model te trainen.
11. Als het model daarmee klaar is, kun je het testen. Voeg in het lege vak een tweet in over Lubach, die je niet hebt gebruikt als voorbeeld om het model mee te trainen. Klik vervolgens op test. Herhaal dit met verschillende tweets. Je kunt ook testen met zelfverzonnen tweets.
Vervolg bespreking
Bespreek klassikaal:
- Hoe goed werkt het model?
- Waar komt dat door?
- Hoe kun je het verbeteren?
- Wat is het verschil met de aanpak van De Groene Amsterdammer?
- Hoe kijk je nu aan tegen het soort onderzoek dat De Groene Amsterdammer gedaan heeft?
- Welke andere onderwerpen zouden interessant zijn om te analyseren op sociale media?
- Wat begrijp je van de manier waarop het Machine Learning model met de voorbeelden aan de slag is gegaan? Wat vind je daarvan?
Materiaal
- Een laptop voor iedere student (of minimaal één laptop per twee studenten)
- Een groot scherm waarop de docent zijn of haar laptopscherm kan delen
- Een gratis account bij AIforkids.co.uk (uitgelegd in het antwoordmodel voor de docent)
Tijdsindicatie
45 minuten, waarvan:
- 5 minuten voor het lezen van het verhaal
- 15 minuten voor het trainen van het model
- 10 minuten voor het bespreken van de labels
- 5 minuten voor het testen
- 10 minuten voor de nabespreking
