Hoe werkt AI?
Om als journalist de kritische vragen te kunnen stellen, of om je studenten dat te leren als journalistiek docent, is het handig als je in grote lijnen weet hoe AI werkt. Je hoeft daarvoor geen technologische kennis te hebben of verstand van codes. Waar het om gaat, is dat je begrijpt wat AI doet om van een bepaalde input, tot een output te komen. Welke stappen worden er eigenlijk gezet?
Als je dit hoofdstuk hebt doorlopen weet je:
Wat is een algoritme?
Heel belangrijk voor AI-systemen, zijn algoritmes. Een algoritme is eigenlijk niet veel meer dan een stappenplan om een taak uit te voeren, vaak in de vorm van een reeks…
computerinstructies. Je kunt een algoritme vergelijken met een recept: het vertelt je hoe je de groenten snijdt, welke rijst je kookt en hoe je de banaan bakt, totdat er een eetbaar gerecht ontstaat. Algoritmen doen niet veel anders. Ze bepalen welke data er nodig zijn, wat ermee gedaan wordt en welk resultaat eruit komt; bijvoorbeeld een getal, categorie, afbeelding of geluid. Met een algoritme vertel je de machine hoe deze van een begin- naar een eindpunt komt.
Kijk maar eens naar onderstaande video.

Twee voorbeelden van algoritmisch denken: je boekenkast en een chatbot
Er zijn verschillende manieren waarop zo’n algoritme kan werken. Soms gaat het om heel eenvoudige regels.
Heb je thuis een boekenkast? Grote kans dat de boeken daarin niet op willekeurige plekken staan. Je kunt op meerdere manieren orde aanbrengen, bijvoorbeeld door je boeken alfabetisch te sorteren of op kleur te groeperen. Welke manier je kiest, is aan jou. Je doel bepaalt hoe je te werk gaat.
Sorteer je je boeken alfabetisch, dan gebruik je bijvoorbeeld dit stappenplan:
- Pak een boek.
- Lees de eerste letter van de naam van de auteur.
- Zoek in je kast andere boeken van auteurs met dezelfde letter: als die er nog niet staan, zoek de dichtstbijzijnde letters in het alfabet, en plaats het boek tussen de voorgaande en volgende letters. Ga verder met stap 1 voor het volgende boek.
- Als er al wel boeken staan met de huidige letter, lees dan de volgende letter van de naam van de auteur.
- Herhaal stap 3 en 4 totdat je een plekje hebt gevonden voor je boek. Ga verder met stap 1 voor het volgende boek.
- Herhaal tot alle boeken alfabetisch gesorteerd in de boekenkast staan.
Als je je boeken op kleur wil groeperen, dan kan je werkwijze er als volgt uitzien:
- Kies een kleur.
- Pak alle boeken waarvan de rug van de kaft grotendeels die kleur heeft.
- Kies een plek in je boekenkast en zet daar alle boeken van de betreffende kleur naast elkaar.
- Herschik eventueel nog wat boeken om kleine nuances binnen de gekozen kleur te verwerken: lichtgeel bij lichtgeel en donkergeel bij donkergeel.
- Ga verder met stap 1 voor de volgende kleur.
- Herhaal tot alle boeken een plek hebben gekregen in de boekenkast.
Een algoritme is eigenlijk niet anders dan zo’n stappenplan. Er zijn vele soorten algoritmes. Elk type dat je kiest hangt af van de taak die je wil uitvoeren. Net als bij de boeken: als je je boeken op kleur wil sorteren, heb je weinig aan een stappenplan op basis van auteursnaam.
Niet alleen voor algoritmes geldt dat het belangrijk is dat je kritisch bent welke je kiest. Het is ook cruciaal dat je relevante kenmerken gebruikt van je boeken (je data). Zulke kenmerken noemen we features. Om alfabetisch te kunnen sorteren moet je beschikken over de naam van de auteur (of titel) in een alfabet dat je kent. De feature ‘auteursnaam’ is noodzakelijk, maar de feature ‘kleur van de kaft’ is in dit geval overbodig.
Chatbots
Dan nu een journalistiek voorbeeld. Ook sommige chatbots werken met eenvoudige algoritmen. Je kent ze wel: je wil iets vragen aan een instantie of redactie, en dat kan via de chat. Zodra je iets intikt, stelt de chatbot zich voor.
‘Hi, ik ben Lisa, een chatbot. Waar kan ik je mee helpen?’
Vervolgens verschijnen er keuzeopties. Van: ‘Ik wil het laatste nieuws weten’, tot: ‘Ik heb een tip voor de redactie’. Zodra je ervoor kiest om het laatste nieuws te ontdekken, verschijnen er opnieuw opties. Wil je iets weten over politiek, sport of klimaat? Op basis van jouw keuzes, weet de chatbot wat hij je moet aanraden.
Dit is een heel simpele vorm van een algoritme. Het algoritme is zo ingesteld, dat hij weet hoe hij op jouw keuzes moet reageren. Dus als je kiest voor ‘Ik wil het laatste nieuws weten’, weet het systeem dat het je een aantal onderwerpen moet voorschotelen om uit te kiezen.
Wat is een algoritme?
Heel belangrijk voor AI-systemen, zijn algoritmes. Een algoritme is eigenlijk niet veel meer dan een stappenplan om een taak uit te voeren, vaak in de vorm van een reeks…
computerinstructies. Je kunt een algoritme vergelijken met een recept: het vertelt je hoe je de groenten snijdt, welke rijst je kookt en hoe je de banaan bakt, totdat er een eetbaar gerecht ontstaat. Algoritmen doen niet veel anders. Ze bepalen welke data er nodig zijn, wat ermee gedaan wordt en welk resultaat eruit komt; bijvoorbeeld een getal, categorie, afbeelding of geluid. Met een algoritme vertel je de machine hoe deze van een begin- naar een eindpunt komt.
Kijk maar eens naar onderstaande video.
Twee voorbeelden van algoritmisch denken: je boekenkast en een chatbot
Er zijn verschillende manieren waarop zo’n algoritme kan werken. Soms gaat het om heel eenvoudige regels.
Heb je thuis een boekenkast? Grote kans dat de boeken daarin niet op willekeurige plekken staan. Je kunt op meerdere manieren orde aanbrengen, bijvoorbeeld door je boeken alfabetisch te sorteren of op kleur te groeperen. Welke manier je kiest, is aan jou. Je doel bepaalt hoe je te werk gaat.
Sorteer je je boeken alfabetisch, dan gebruik je bijvoorbeeld dit stappenplan:
- Pak een boek.
- Lees de eerste letter van de naam van de auteur.
- Zoek in je kast andere boeken van auteurs met dezelfde letter: als die er nog niet staan, zoek de dichtstbijzijnde letters in het alfabet, en plaats het boek tussen de voorgaande en volgende letters. Ga verder met stap 1 voor het volgende boek.
- Als er al wel boeken staan met de huidige letter, lees dan de volgende letter van de naam van de auteur.
- Herhaal stap 3 en 4 totdat je een plekje hebt gevonden voor je boek. Ga verder met stap 1 voor het volgende boek.
- Herhaal tot alle boeken alfabetisch gesorteerd in de boekenkast staan.
Als je je boeken op kleur wil groeperen, dan kan je werkwijze er als volgt uitzien:
- Kies een kleur.
- Pak alle boeken waarvan de rug van de kaft grotendeels die kleur heeft.
- Kies een plek in je boekenkast en zet daar alle boeken van de betreffende kleur naast elkaar.
- Herschik eventueel nog wat boeken om kleine nuances binnen de gekozen kleur te verwerken: lichtgeel bij lichtgeel en donkergeel bij donkergeel.
- Ga verder met stap 1 voor de volgende kleur.
- Herhaal tot alle boeken een plek hebben gekregen in de boekenkast.
Een algoritme is eigenlijk niet anders dan zo’n stappenplan. Er zijn vele soorten algoritmes. Elk type dat je kiest hangt af van de taak die je wil uitvoeren. Net als bij de boeken: als je je boeken op kleur wil sorteren, heb je weinig aan een stappenplan op basis van auteursnaam.
Niet alleen voor algoritmes geldt dat het belangrijk is dat je kritisch bent welke je kiest. Het is ook cruciaal dat je relevante kenmerken gebruikt van je boeken (je data). Zulke kenmerken noemen we features. Om alfabetisch te kunnen sorteren moet je beschikken over de naam van de auteur (of titel) in een alfabet dat je kent. De feature ‘auteursnaam’ is noodzakelijk, maar de feature ‘kleur van de kaft’ is in dit geval overbodig.
Chatbots
Dan nu een journalistiek voorbeeld. Ook sommige chatbots werken met eenvoudige algoritmen. Je kent ze wel: je wil iets vragen aan een instantie of redactie, en dat kan via de chat. Zodra je iets intikt, stelt de chatbot zich voor.
‘Hi, ik ben Lisa, een chatbot. Waar kan ik je mee helpen?’
Vervolgens verschijnen er keuzeopties. Van: ‘Ik wil het laatste nieuws weten’, tot: ‘Ik heb een tip voor de redactie’. Zodra je ervoor kiest om het laatste nieuws te ontdekken, verschijnen er opnieuw opties. Wil je iets weten over politiek, sport of klimaat? Op basis van jouw keuzes, weet de chatbot wat hij je moet aanraden.
Dit is een heel simpele vorm van een algoritme. Het algoritme is zo ingesteld, dat hij weet hoe hij op jouw keuzes moet reageren. Dus als je kiest voor ‘Ik wil het laatste nieuws weten’, weet het systeem dat het je een aantal onderwerpen moet voorschotelen om uit te kiezen.
Wat is Rule Based AI?
Als je bovenstaande scenario’s voor het sorteren van je boeken of de chatbot door een computer laat uitvoeren, hoeft er geen AI of machine learning aan te pas te komen. ..
Een programmeur kan deze algoritmes met wat simpele regels implementeren en de computer kan de taak keer op keer goed uitvoeren.
Dit type AI heet ook wel rule based (‘regelgebaseerd’). Dat wil zeggen: Mensen stellen regels op, waar de machine zich heel direct aan dient te houden. Bijvoorbeeld: Als de gebruiker optie A (‘Ik wil het laatste nieuws weten’) kiest, reageer je met antwoord A (‘In welk onderwerp ben je geïnteresseerd?’).
Ingewikkelder zijn de algoritmes bij andere typen van AI. Neem het deelgebied Machine Learning.
Wat is Machine Learning?
Stel, je wil net zoals in de één van de eerdere video’s, een computersysteem leren afbeeldingen van honden en katten te onderscheiden.
Als je dat doet door alleen afbeeldingen van de twee diersoorten te tonen, dan spreken we van machine learning. Het is het proces waarbij computers leren aan de hand van voorbeelden; zonder het programmeren van expliciete regels.

In een ML-proces leert een computer dus zelf wat het moet doen aan de hand van voorbeelden uit het verleden. Dankzij ML herkennen computers patronen die wij mensen over het hoofd zien. Dat maakt ML-toepassingen interessant.
Denk bijvoorbeeld aan vertaalmachines, zoals Google Translate. Voordat ML om de hoek kwam kijken, bestonden zulke vertaalprogramma’s uit expliciete regels. Ze konden woorden alleen precies zo vertalen als in het woordenboek stond opgegeven. Tegenwoordig gebruiken vertaalmachines enorme hoeveelheden tekst in meerdere talen. Ze leiden daaruit zelf af hoe een woord of een zin in een bepaalde taal geformuleerd moet worden.
Er zijn tal van toepassingen waarin ML een rol speelt. Denk maar aan spamfilters, gezichtsherkenning en advertenties. Ook Netflix past Machine Learning toe om te bepalen welk aanbod het jou voorschotelt.
Deep Learning gaat zelfs nog een stapje verder. Daarbij biedt je de machine alleen data aan, zonder die data van labels te voorzien.
Als je een ML-systeem het verschil tussen honden en katten wil leren, biedt je het eerst foto’s aan waarbij je aangeeft of het om een hond of een kat gaat. Dat zijn de labels. Bij deep learning bied je het systeem alléén de foto’s aan, zonder die labels dus.
Op basis van enkel data (bijvoorbeeld de honden- en kattenfoto’s) ontdekt een Deep Learning AI-systeem zelfstandig patronen en regels. Om dat te kunnen, maakt DL gebruik van neurale netwerken. Ingewikkeld? Dat valt wel mee. Bekijk onderstaande video’s maar eens.

Drie soorten Machine Learning
Binnen ML onderscheiden we vaak verschillende categorieën. Het verschil zit hem in het soort data die je tot je beschikking hebt, en de taak die je wil uitvoeren.
We bespreken hieronder de belangrijkste categorieën van Machine Learning: Supervised, Unsupervised en Reinforcement Learning.
Supervised learning
Stel, je wil een nieuwe taal leren, zoals Engels. Er zijn meerdere manieren waarop je dat kunt aanpakken. Je kunt bijvoorbeeld een woordenboek aanschaffen en vertalingen uit je hoofd leren. Het woordenboek vertelt je dat ‘huis’ zich vertaalt als ‘house’ en ‘kat’ als ‘cat’. Door deze woordjes voor jezelf te herhalen, bouw je een woordenschat op en kun je steeds beter uit de voeten met je nieuwe taal.
Deze aanpak is een voorbeeld van supervised learning (‘gecontroleerd leren’). De uitkomsten van wat je wil leren zijn al van tevoren bekend: je hebt de vertalingen tot je beschikking, en je wil dat het model leert om diezelfde vertalingen zelf te vinden. Je hebt bij Supervised Machine Learning dus gelabelde data nodig (de vertalingen van woorden in dit geval). Het ML-algoritme leert om die uitkomsten te reproduceren.
Meer in journalistieke context kun je bij Supervised Machine Learning denken aan het voorbeeld van de miljoenen haattweets. Daarbij stelden de journalisten steeds de vraag waarover een haattweet ging. Ze gebruikten daarvoor de labels ‘lichaam’, ‘leeftijd’, ‘gender’, ‘religie’ en ‘etniciteit’.
Bedenk goed dat supervised learning begint bij mensen. De selectie van de voorbeelden, de gekozen labels en de toekenning ervan aan de verschillende voorbeelden (de data) worden door mensen bepaald en uitgevoerd. Met deze door mensen gelabelde voorbeelden wordt vervolgens het AI-systeem getraind. De mens is hier de supervisor, en zo komt dit type machine learning ook aan de naam: supervised learning.
Let op: jij bent dus verantwoordelijk voor wat het AI-systeem leert.
Unsupervised learning
Naast Supervised Machine Learning, bestaat er Unsupervised Machine Learning. Laten we het voorbeeld over het leren van een taal er weer bij halen.
Je kan woordjes uit je hoofd leren, zoals in het eerste voorbeeld. Maar een andere aanpak kan zijn om Engelstalige televisie te kijken (zonder ondertiteling) of een Engelstalig boek te lezen. Omdat je geen vertalingen tot je beschikking hebt, moet je zelf herleiden wat een woord betekent. Dit klinkt lastig, maar als je jezelf maar genoeg blootstelt aan een nieuwe taal ga je vanzelf patronen herkennen. Het valt je op dat mensen ‘I’ gebruiken als ze over zichzelf praten en ‘you’ als ze tegen een ander praten. Hierdoor leer je dat je deze woorden zelf ook op die manier kunt gebruiken.
Deze aanpak is een voorbeeld van unsupervised learning (‘ongecontroleerd leren’). Je weet nu niet van tevoren wat je precies moet leren, maar door voldoende voorbeelden in de juiste context, word je steeds beter in je nieuwe taal. Unsupervised Machine Learning werkt op dezelfde manier: het leert zelfstandig en al doende.
Om Unsupervised Machine Learning beter uit te leggen, nemen we het kat-en hond-voorbeeld uit de introductie er weer bij. Maar in dit geval geven we géén labels aan de foto’s van de dieren. Daardoor weet het systeem niet welke afbeelding een kat of juist een hond bevat. In plaats van gelabelde data gebruik je nu ongelabelde data, waarin het ML-algoritme zelf op zoek gaat naar patronen. Zo leert het unsupervised learning systeem in dit voorbeeld, door de verschillende afbeeldingen te bekijken en te vergelijken, dat er duidelijke verschillen en overeenkomsten bestaan tussen afbeeldingen van honden en afbeeldingen van katten. Het leert de patronen herkennen en ontdekt zo wat kenmerkend is voor honden en voor katten.
Clusteren
Wat een unsupervised systeem doet is ‘clusteren’. Dat is het zoeken in je data naar voorbeelden die op elkaar lijken. Zo deelt het systeem de voorbeelden op in groepen. Clustering wordt veel toegepast op datasets met informatie over personen. Voor bedrijven is het vaak interessant om groepen klanten te identificeren; zij kunnen hun diensten of reclames dan variëren van groep tot groep. Denk maar eens aan de reclames die je krijgt op Instagram of Facebook. Met clustering maak je zulke groepen, zonder dat je van tevoren hoeft aan te geven hoeveel groepen er zijn en welke persoon in welk groepje valt.
Clustering kan ook gebruikt worden om afbeeldingen met veel overeenkomsten te groeperen. Zo kan een clusteringalgoritme hondenfoto’s van kattenfoto’s onderscheiden, zonder te begrijpen wat er op de verschillende afbeeldingen staat. Het is dan de mens die er vervolgens begrip aan toe kent door er een label aan te hangen.
Een praktijkvoorbeeld van Unsupervised Learning: hoe complottheorieën zich online verspreiden
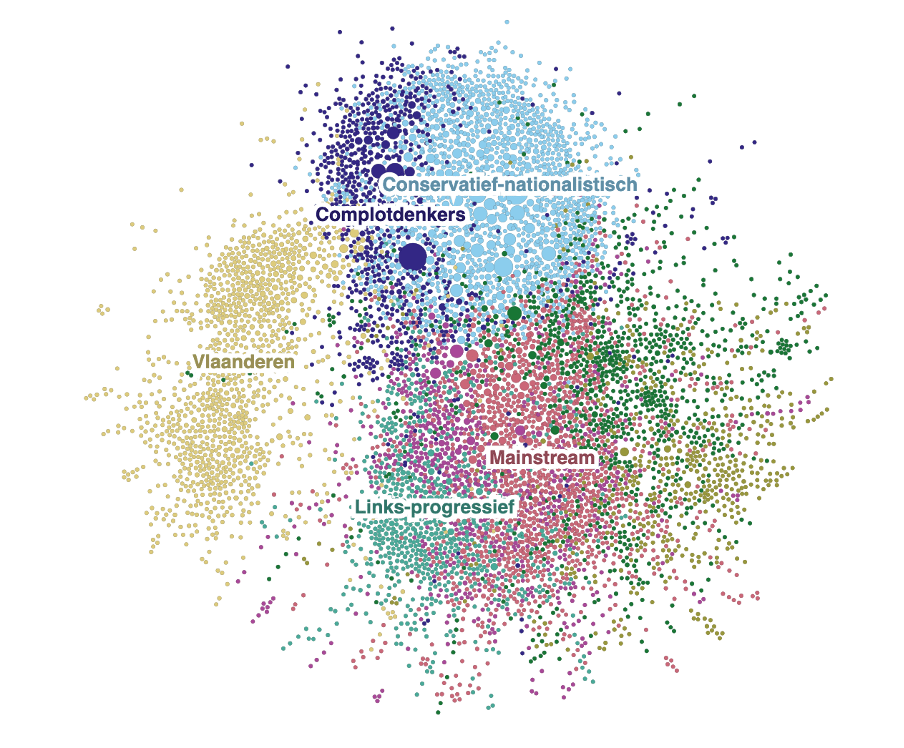
Journalisten gebruiken clustering wanneer ze interacties tussen gebruikers op sociale netwerken in kaart brengen. Bijvoorbeeld als ze willen weten hoe content van influencers zich verspreidt of hoe complottheorieën hun weg vinden naar de ‘mainstream media’. Rosa van Gool en Coen van de Ven (De Groene Amsterdammer) onderzochten in 2020 hoe mensen corona en 5G met elkaar in verband brachten op social media. Mensen die elkaars berichten liketen, retweeten of erop reageerden, creëerden zo ‘relaties’. Al die onderlinge relaties leverde een beeld op (zie onder) van groepen mensen die op inhoud met elkaar te maken hebben. Zo vormden zij clusters.

Door uit te zoomen kun je zo deze verschillende groepen, clusters van mensen of inhoud, van elkaar onderscheiden. Vervolgens kun je er alsnog een label aan toekennen, zodat je nader onderzoek kunt doen naar bijvoorbeeld complotdenkers of links-progressieven.
Let op: het toekennen van labels aan de clusters, zoals hier in het voorbeeld ‘mainstream’ of ‘Vlaanderen’ doen mensen en niet het AI-systeem. Door menselijke analyse van de twitteraars binnen een cluster, ontstond de mogelijkheid om het type twitteraar te classificeren.
Zo zie je maar: ook hier is labeling mensenwerk en daardoor arbitrair. Een goede verantwoording is dan ook nog altijd nodig om de selectie van voorbeelden en de bijbehorende labels uit te leggen aan collega’s, bronnen en publiek.
Reinforcement learning
Het derde en laatste type Machine Learning is Reinforcement Learning. Om uit te leggen hoe dit werkt, gaan we opnieuw terug naar het voorbeeld over het leren van een nieuwe taal.
We hebben het gehad over het leren van een nieuwe taal door woorden te leren uit een woordenboek, of door televisie te kijken in de betreffende taal, zonder ondertiteling. Een derde manier om Engels te leren, is door te reizen naar een land waar het de voertaal is, en je daar onder de mensen te begeven. Je gaat een gesprek aan in het Engels en krijgt feedback wanneer je een fout maakt. Deze feedback kan expliciet zijn (iemand corrigeert je) of impliciet (je vangt op dat anderen het anders zeggen dan jij). Dit helpt je om beter te worden. Dit lijkt op hoe een peuter leert praten. Het kind zegt ‘ik loopte’, krijgt van z’n ouders te horen: ‘ik liep’, maakt de fout misschien nog een paar keer, maar kiest uiteindelijk steeds vaker voor de juiste vervoeging.
Deze aanpak is een voorbeeld van Reinforcement Learning (‘versterkend leren’). Je leert door vallen en opstaan: door fouten te maken, correctie en beloning.
In ML wordt Reinforcement Learning gebruikt voor complexe toepassingen zoals robotbewegingen, zelfrijdende auto’s of het spelen van games. Als je zelf met ML aan de slag gaat, is de kans klein dat je met Reinforcement Learning te maken krijgt. Je hebt vaak geen toegang tot de nodige feedback, en zult dus met supervised of unsupervised learning aan de slag moeten.
Als gebruiker heb je waarschijnlijk wel talloze keren bijgedragen aan AI-systemen die Reinforcement Learning gebruiken. Denk bijvoorbeeld aan sociale media waarbij ingewikkelde algoritmes proberen te voorspellen wat jij wel en niet interessant vindt. Like jij een bericht dat Instagram je voorschotelde? Als gebruiker geef je zo steeds feedback aan het systeem. Op die momenten wordt Machine Learning gecombineerd met input van mensen. De menselijke input fungeert dan ook als data. Blijkbaar viel de Instagram-post in de smaak.
Reinforcement learning wordt niet alleen gebruikt op social media, maar ook bij advertenties van Google. Heb je wel eens meegemaakt dat je een advertentie werd voorgeschoteld, met daarbij de vraag ‘Was deze advertentie nuttig?’. Als je op ‘Nee’ klikt, volgt de vraag ‘Waarom niet?’. Ook dat is informatie die het algoritme gebruikt om zich te verbeteren.
Generatieve AI voor journalisten
Als je het bovenstaande gelezen hebt, weet je nu wat Machine Learning inhoudt. Sinds een tijdje is er nog een nieuwe vorm van AI waarover we veel horen: generatieve AI.
Dat is een vorm van AI die content kan genereren, zoals teksten, video of afbeeldingen. Met name sinds de opkomst van ChatGPT is dit een hot topic geworden.
Maar wat is het en hoe werkt het precies?
Generatieve AI vs Classificerende Machine Learning
Laten we beginnen met wat generatieve AI niet is.
Machine Learning wordt (zoals je misschien al gelezen hebt) vaak gebruikt voor classificatietaken. Je kunt er vragen mee beantwoorden als “Bevat dit plaatje een hond?”, “Wat is het onderwerp van deze tekst?”, “Is deze review positief of negatief?”, “Is dit een gezicht?”.
Met generatieve AI kun je het tegenovergestelde doen. Je vraagt het model niet het onderwerp van een tekst te herkennen, maar jij geeft het onderwerp, het model maakt vervolgens de tekst.
Nog een voorbeeld: Een Machine Learning Model kan aangeven of er een hond op een afbeelding staat. Met generatieve AI draai je het om en kun je het model vragen om een plaatje van een hond te maken.
De wijze waarop een generatieve AI dit voor elkaar krijgt, lijkt in de kern op Machine Learning. Machine Learning modellen zijn namelijk getraind op enorme hoeveelheden voorbeelden. Bij generatieve AI is dat niet anders. ChatGPT is bijvoorbeeld getraind op enorme hoeveelheden teksten.
Er is echter een belangrijk verschil tussen generatieve AI en Machine Learning. Bij een classificatietaak heeft het model een helder doel: zo veel mogelijk honden correct classificeren. Een afbeelding is een hond of het is geen hond.
Generatieve AI heeft hier een probleem. Er zijn namelijk oneindig veel mogelijkheden voor een goed antwoord op de opdracht: teken een plaatje van een hond. Hoe zorg je ervoor dat generatieve AI kan komen tot een nieuw, nog nooit geproduceerd plaatje van een hond, dat daadwerkelijk een plaatje van een hond is?
Om generatieve AI te kunnen gebruiken hoef je in principe niet te weten hoe het werkt. Start ChatGPT op, stel een vraag en klaar: je gebruikt generatieve AI. Maar wil je kritische vragen stellen of problemen identificeren (je bent tenslotte journalist!) dan helpt het om de black box op een kiertje te zetten en een kijkje te nemen aan de achterkant.
Hieronder lees je kort welke technieken verschillende typen generatieve AI gebruiken en hoe ze werken.
GPT modellen – zoals gebruikt in Chat GPT.
Laten we beginnen met een tool die in korte tijd veel bekendheid heeft verworven: ChatGPT.
Deze tool levert soms heel overtuigende teksten op, die vol onzin blijken te zitten. Hallucineren, noemen we dat ook wel. Het kwam Bard (vergelijkbaar met ChatGPT, maar van de concurrent van OpenAI: Google) duur te staan. Toen het model in een promotiefilmpje dingen bleek te verzinnen, kelderde de beurswaarde spontaan met 8%.
Om te begrijpen waar hallucinaties vandaan komen, en om de output van Large Language Models op waarde te kunnen schatten, is het handig als je weet wat het model doet zodra jij een prompt (of opdracht) intikt.
Transformer
De ‘T’ in ChatGPT staat voor Transformer. Dat is een techniek die gebruikt wordt om een model te trainen. Deze techniek is anders dan bij Machine Learning.
Wat ChatGPT doet, als we het erg versimpelen, is continu voorspellen wat het volgende woord in een tekst is. Het doet dat op basis van statistische analyses van ontzettend veel door mensen geschreven teksten. Een voorbeeld. Stel je voor dat je onderstaande tekst hebt en wil weten welk woord op de puntjes moet staan:
Wil je suiker in je … ?
Doordat het model ontzettend veel voorbeelden heeft gezien, kan het berekenen dat de kans vrij groot is dat op de puntjes ‘koffie’ of ‘thee’ moet staan, en dat de kans dat hier ‘ogen’ moet staan juist klein is. ChatGPT berekent op deze manier continu welk volgend woord het meest waarschijnlijk is.
Als journalist is het belangrijk dat je weet dat Large Language Modellen (LLM’s) zoals ChatGPT simpel gezegd een statistische voorspelling doen van woorden. Het model begrijpt de inhoud van de woorden niet. Daardoor kan het soms grammaticaal correcte zinnen maken, die toch totaal niet kloppen. Dat vergt een bewuste, kritische blik van journalisten.
Embeddings
Je weet inmiddels dat LLM’s statistische analyses doen om teksten te genereren. Een cruciaal probleem daarbij is context. Een verhaal is meer dan een willekeurige collectie van grammaticaal correcte zinnen. En zinnen zijn meer dan een willekeurige collectie van woorden. De context doet ertoe.
Transformers helpen het model om rekening te houden met de context van woorden. Dankzij transformers weet het model dat ‘bos’ en ‘boom’ waarschijnlijk meer met elkaar te maken hebben dan ‘bos’ en ‘plafond’. Maar hoe weet het model dat?
Je moet de uitkomst van het werk van transformers zien als een virtuele ruimte vol punten. Ieder punt staat voor een woord, en de afstand tot andere woorden laat zien hoe groot de kans is dat het ene woord te maken heeft met het andere woord. Die transformatie van woorden naar punten heten embeddings.
De embedding voor ‘bos’ staat daar letterlijk dichterbij ‘boom’ dan bij ‘plafond’, omdat bomen en bossen vaker in dezelfde context genoemd worden dan bomen en plafonds.
Ook de positie van een woord in een zin wordt omgezet in een embedding. Deze positional embeddings zijn cruciaal bij het bepalen van de betekenis van zinnen. Denk maar aan de zinnen “de kat eet de muis” of “de muis eet de kat”, die door een klein verschil in woordpositie iets heel anders betekenen.
De wiskunde achter modellen als GPT bevat nog veel meer stappen en berekeningen, maar de kern blijft hetzelfde: woorden worden omgezet naar getallen die een punt in de virtuele ruimte krijgen, waardoor het model kan berekenen welke woorden waarschijnlijk samen horen, in welke volgorde en volgens welke grammaticale regels. Dat maakt dat tools op basis van een GPT model zo slim lijken.
Pre-trained
Je weet nu waar de ‘T’ in ChatGPT voor staat. De P staat voor ‘pre-trained’ en gaat over de manier waarop deze modellen ontwikkeld zijn.
Tijdens het trainingsproces moet het model steeds een volgend woord of stuk tekst voorspellen of een gat in een bestaande tekst opvullen. Geeft het een juist antwoord? Dan wordt het beloond. Als ChatGPT een kloppende verbinding heeft gelegd tussen twee woorden, dan krijgt die verbinding in het model meer gewicht.
De pre-training gebeurt vóórdat het model gebruikt wordt door de gebruikers van een tool als ChatGPT. Het model heeft dan de leerfase afgerond. Het leert dus niet tijdens het gebruik, al kan er wel gebruikersdata verzameld worden om het model in een volgende trainingsronde te verbeteren.
De meest krachtige modellen zoals GPT-3 bevatten netwerken met miljarden gewichten die getraind zijn door ze bloot te stellen aan terrabytes aan data. Door hun omvang worden deze modellen ook wel Large Language Models genoemd.
Blijf scherp
Er zijn echter ook tekortkomingen, waar je als journalist rekening mee moet houden.
Omdat het model statistische analyses uitvoert om woordsamenstellingen te voorspellen, is het goed in correcte zinnen schrijven. Het begrijpt woorden echter niet zoals wij dat doen. Je kunt LLM’s daarom niet vertrouwen op inhoud. Zoals Carissa Véliz (AI-expert bij Oxford University) het verwoordt
‘Deze systemen zijn bedoeld om plausibele antwoorden te geven op basis van statistische analyse – ze zijn niet ontworpen om waarheidsgetrouw te antwoorden’
Dit verandert niet naarmate het model op (nog) meer data getraind wordt. De manier waarop het model werkt, blijft namelijk hetzelfde.
Ook bias is een bekend en hardnekkig probleem van generatieve AI. Een model als GPT is getraind op grote hoeveelheid teksten van mensen. Mensen hebben per definitie vooroordelen – hun teksten dus ook. En omdat GPT op dit soort teksten getraind is, neemt het de vooroordelen over.
OpenAI probeert dit te voorkomen door mensen in Kenia voor minder dan twee euro per uur de output van ChatGPT te laten controleren. Wanneer het model uit de bocht vliegt, worden de tool regels opgelegd. Zo zie je dat wanneer je vraagt naar Israël en Palestina, het model tegenwoordig een keurig, genuanceerd antwoord geeft, terwijl het eerder de vrijheid van Israel verdedigde, maar die van Palestina niet. Het in toom houden van ChatGPT en zorgen dat het geen uitspraken doet die gevoelig liggen, is een voortdurende strijd (meer hierover lees je hier). Het is goed om dit in je achterhoofd te houden wanneer je ChatGPT gebruikt.
Dit alles heeft gevolgen voor de manier waarop journalisten ChatGPT inzetten. Een veel gehoord advies is om het te gebruiken voor vorm, maar niet voor inhoud. ChatGPT kan bijvoorbeeld goed helpen bij het bedenken van koppen, het samenvatten van stukken, het schrijven van social mediaposts, het aanpassen van je taalniveau, vertalingen of het bedenken van interviewvragen – mits je als journalist de nodige inhoud levert. Om ChatGPT te vragen om feiten of uitleg, is minder verstandig. Veel redacties hebben inmiddels richtlijnen. (Meer daarover lees je hier. En een lesopdracht over richtlijnen, vind je hier).
Generatieve AI om plaatjes uit tekst te genereren
Generatieve AI kun je niet alleen gebruiken om teksten te schrijven. Het kan ook plaatjes genereren op basis van tekst.
Daarvoor moeten grof gezegd twee problemen opgelost worden.
1. Welk plaatje hoort bij welk stuk tekst ? (Met andere woorden: Wanneer vinden we een plaatje goed passen bij de ingevoerde prompt?)
2. Hoe kom je tot een geheel nieuw gegenereerd plaatje – niet slechts een plaatje dat ook al in de trainingsdata van het gebruikte model zat?
We leggen uit hoe de technieken van de meest populaire tools met deze problemen omgaan.
CLIP – gebruikt in Dall-E & Stable Diffusion
De eerste techniek die gebruikt wordt door onder andere Dall-E en Stable Diffusion heet CLIP (kort voor Contrastive Language-Image Pre-Training) en komt van de makers van ChatGPT: openAI. Het lost het eerste probleem van het genereren van plaatjes op: welke plaatje hoort bij welke tekst?
CLIP is een classificeringsmodel zoals we kennen uit Machine Learning. Het bepaalt namelijk welk prompt bij welk plaatje hoort, en bij welke plaatjes niet. Bij de prompt ‘hond’ hoort bijvoorbeeld een plaatje van een hond, maar geen afbeelding van een kat.
Omdat CLIP gebruikt maakt van dezelfde transformer-technologie als GPT, heeft het de mogelijkheid om zogenaamde image-embeddings te leren: die geven aan welke plaatjes en prompts dichtbij elkaar liggen qua betekenis. Die embeddings geven de kaders aan waarbinnen de nieuwe afbeelding gegenereerd moet worden. Dall-E gebruikt dit als eerste stap voor het genereren van nieuwe afbeeldingen.
Diffusion modellen zoals gebruikt in Midjourney, Dall-E en Stable Diffusion
Diffusion modellen zijn een oplossing voor het tweede probleem van het genereren van plaatjes: hoe zorgen we ervoor dat een model een volledig nieuw plaatje genereert en niet een plaatje kopieert uit de trainingsdata?
Diffusion modellen lossen dit op met een slimme truc: het model is getraind om te starten met plaatje dat enkel bestaat uit random gegenereerde ruis. Een neuraal netwerk zet deze ruis vervolgens stap voor stap om tot een plaatje. Doordat het model start met ruis, is de input telkens anders en dat maakt dat ook de output anders is.
Het model is getraind door het te voeden met scherpe plaatjes, waar in stappen steeds meer ruis aan is toegevoegd. Vervolgens wordt het model gevraagd om het originele plaatje te recreëren. Zo leert het model om vanuit ruis een afbeelding op te leveren.
Generative Adversirial networks (GAN’s)
Een andere oplossing voor de twee vraagstukken die we hierboven noemden, zijn Adversarial Networks. Deze techniek combineert twee netwerken, die opereren als elkaars voor- en tegenstander. Het ene netwerk is de generator, het ander de discriminator.
De generator produceert steeds weer een nieuw plaatjes (bijvoorbeeld vanuit ruis zoals met diffusion technologie, of vanuit een ander plaatje dat aangepast wordt). De taak van de discriminator is om te keuren hoe goed het gegenereerde plaatje is. Het doet dat door te leren onderscheid te maken tussen echte afbeeldingen en AI-gegeneerde plaatjes.
Beide netwerken hebben een tegenovergestelde beloning en helpen zo elkaar om beter te worden. De generator wil plaatjes maken die zo lastig mogelijk van echt te onderscheiden zijn en de discriminator wil juist dat onderscheid zo goed mogelijk maken. De twee systemen zijn continu met elkaar in ‘strijd’ en maken elkaar daardoor steeds beter.
Adversarial training helpt te focussen op datgene waar je niet goed in bent. Dat zou anders immers tegen je kunnen worden gebruikt door je tegenstander. GANs worden veel gebruikt bij het genereren van plaatjes, maar kunnen ook ingezet worden voor tekst of audio.
Veel generatieve modellen gebruiken combinaties van technieken, zoals primair Diffusion en GAN. De precieze implementatie en training van de modellen varieert enorm.
Bias
We noemden bias al als een risico bij het gebruik van ChatGPT. Bij modellen die afbeeldingen genereren, is dat niet anders. Zo ontdekte Bloomberg dat de vraag naar een afbeelding van een advocaat wel héél vaak een witte, oudere man opleverde. Hoe lager de sociaaleconomische status van een beroep, hoe vaker er een vrouw te zien was op de afbeelding, en hoe donkerder de huidskleur. Bij het gebruik van dit soort tools is het dan ook van belang om scherp te blijven. Wat vind je van de output? Moet je je prompt aanpassen om bias te voorkomen?
Het model en de tool
Het brede publiek kan al een tijd gebruik maken van Generatieve AI, dankzij tools als Dall-E en ChatGPT. Bij het gebruik van deze tools, is het verstandig om onderscheid te maken tussen de tool en het onderliggende model. Het model doet de wiskunde aan de achterkant, de tool is de gebruiksvriendelijke voorkant, waarmee jij uit de voeten kan. Je kunt het vergelijken met een app: wat je ziet en gebruikt is de voorkant (de tool). De code aan de achterkant (het model) zie je niet.
Helaas is het in de praktijk niet altijd makkelijk om onderscheid te maken tussen de tool en het model. De tool geeft een antwoord op jouw prompt. Of dit antwoord gelijk is aan het antwoord dat het model zou geven, weet je niet.
Een voorbeeld: je vraagt aan ChatGPT om een mop te vertellen over Afrikanen en krijgt daarop het antwoord dat het maken van grappen als beledigend of kwetsend ervaren kan worden. Wel wil ChatGPT je een luchtig grapje vertellen, meldt het. Er volgt een poging tot een grap.
Je weet dan niet of het model deze uitkomst bepaald heeft, of dat het de tool is. In de tool zit namelijk een moderatielaag ingebouwd die op basis van regels bepaalde vragen afwijst, omdat ze bijvoorbeeld racisme in de hand kunnen werken. Het onderscheid is niet altijd duidelijk.
Deze scheiding tussen tool en model verklaart ook waarom ChatGPT het ene moment een vraag nog wel wil beantwoorden terwijl diezelfde vraag later niet meer beantwoord wordt. Het model is in die korte tijd waarschijnlijk niet veranderd, maar de moderatielaag in de tool wel. Dit laat ook zien waarom er verschillen zijn tussen tools die (bijna) dezelfde modellen gebruiken, maar hele andere reacties geven. De tool geeft ruimte om de normen en waarden van de makers te verwerken, meer dan in het model.
Meer weten? Bekijk dan ook deze video’s eens.


